Have you ever wished you could use AI inside ServiceNow, without depending on OpenAI, Azure, or any other cloud provider? In this post, I’ll show you how I integrated a locally hosted large language model (LLM) with my ServiceNow Personal Developer Instance (PDI) using a ServiceNow MID Server running on my local machine.
With this setup, you can send data from ServiceNow to a local AI model, process it, and return useful responses, all without exposing sensitive data to external services. You’ll see how to:
Let’s get started.
Solution Overview
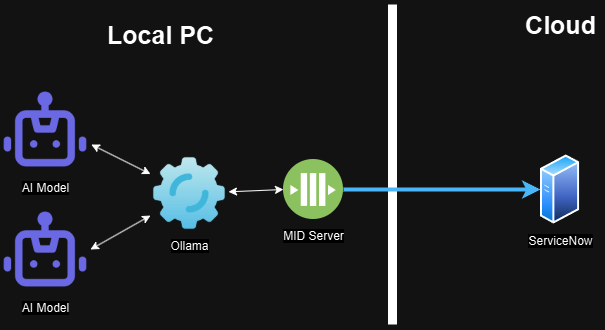
The architecture leverages ServiceNow's MID (Management, Instrumentation, and Discovery) Server to establish a secure connection between ServiceNow and locally hosted LLM capabilities through Ollama.
In this setup, a ServiceNow instance accesses a locally hosted LLM through a MID Server. While this demonstration uses a locally installed MID Server, enterprise implementations typically deploy MID Servers on dedicated hardware within their network infrastructure.
The MID Server follows a pull-based communication model, ensuring security by preventing ServiceNow from initiating direct connections to customer infrastructure. Instead, the MID Server periodically polls ServiceNow for instructions, executes them within the customer environment, and returns the results to ServiceNow. This architecture maintains network segmentation while enabling powerful integration capabilities.
For the LLM integration, the workflow operates as follows:
This architecture keeps everything inside your own environment. No external APIs. No cloud costs. Just full control.
Setting up the MID Server
If you already have a MID Server running locally, you can skip this step. If not, here’s how to set one up using WSL on Windows:
The first step is to go to your ServiceNow instance, and download the MID Server package for Linux. You do that by navigating to MID Server > Downloads
Download the version that fits the Linux distribution you are using. If you are using the standard Ubuntu version that comes with WSL, select the 64-bit DEB version under the Linux Downloads section
Once it has been downloaded, follow the installation guide provided by ServiceNow, to setup the MID server: MID Server Installation Guide
Once installed and validated, your MID Server is ready to act as a local gateway between ServiceNow and the AI model.
Setting up Ollama
To run an AI model on your machine, we’ll use Ollama, which supports multiple open-source LLMs and has a simple API. The easiest way to get started is with Docker. It is easy to set up using the Docker Desktop client, which can be downloaded here: Download Docker Desktop . Once you have Docker Desktop running, go to Images and search for Ollama:
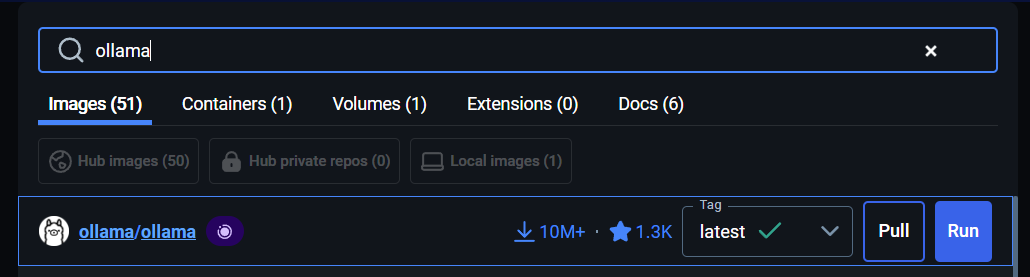
Choose the ollama/ollama option and press Pull button to download Ollama. Once it has been downloaded, navigate to Images, locate ollama and press the Play button to start Ollama:

Be sure to set the port to 11434, as this port will be used later:
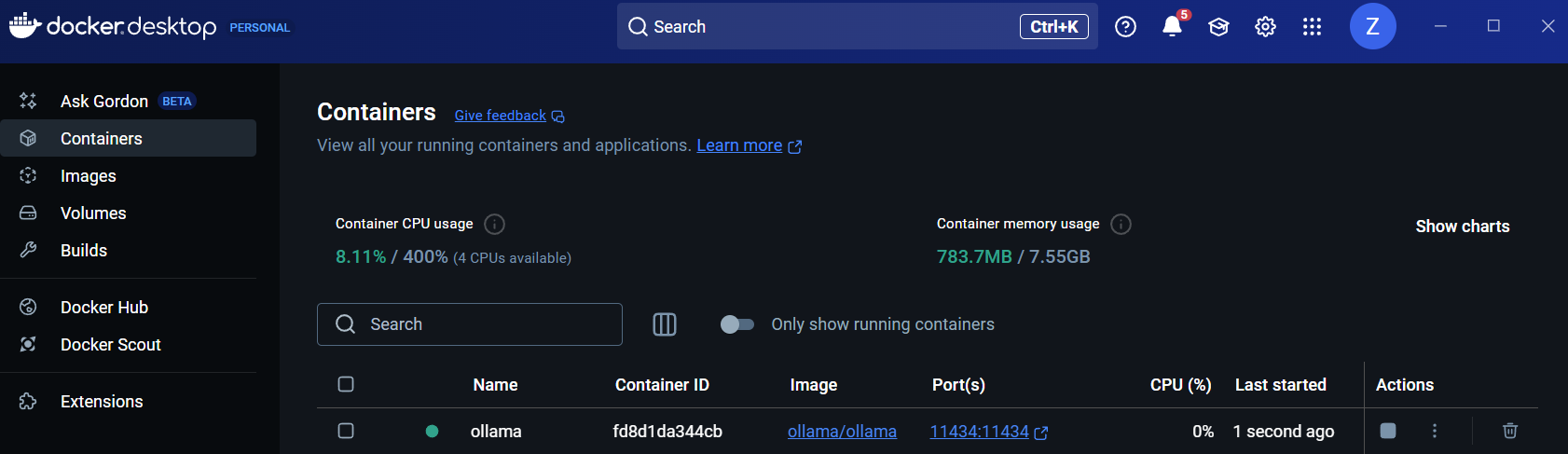
Verify that the Ollama container is running by navigating to Containers and locate the ollama container:
Press the container, and navigate to the Exec tab to execute commands:
From here, we will install and run an AI model inside of Ollama. To get a full overview of all the currently available models, head to the Ollama website here: Ollama website. For this demonstration, we will download and setup the Gemma3 4B model, by running the command:
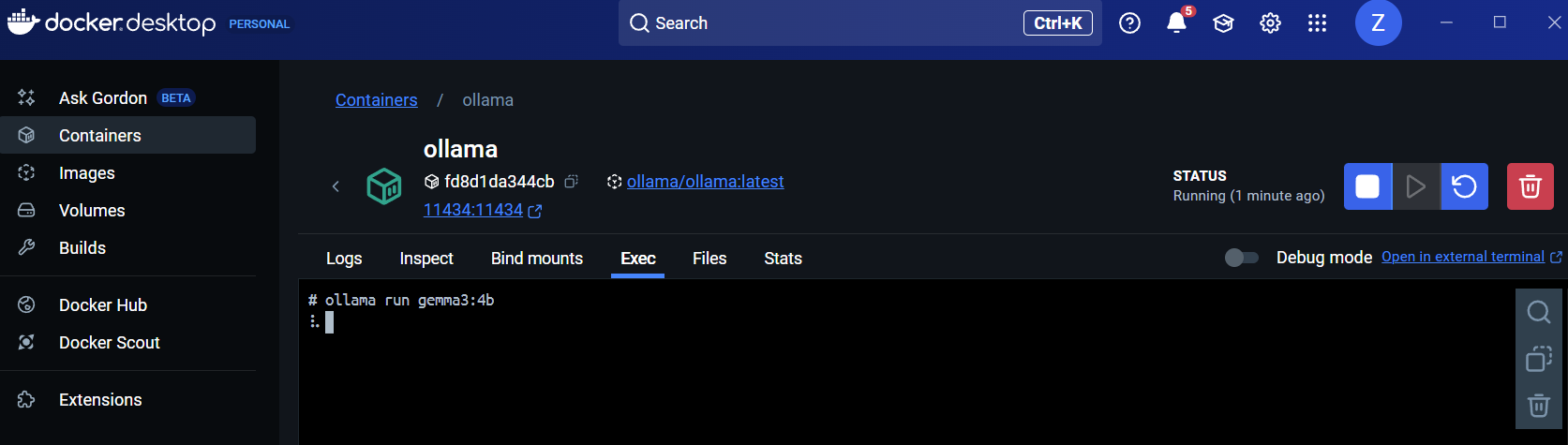
To test it, type a question and hit enter, you should see a response in the terminal:
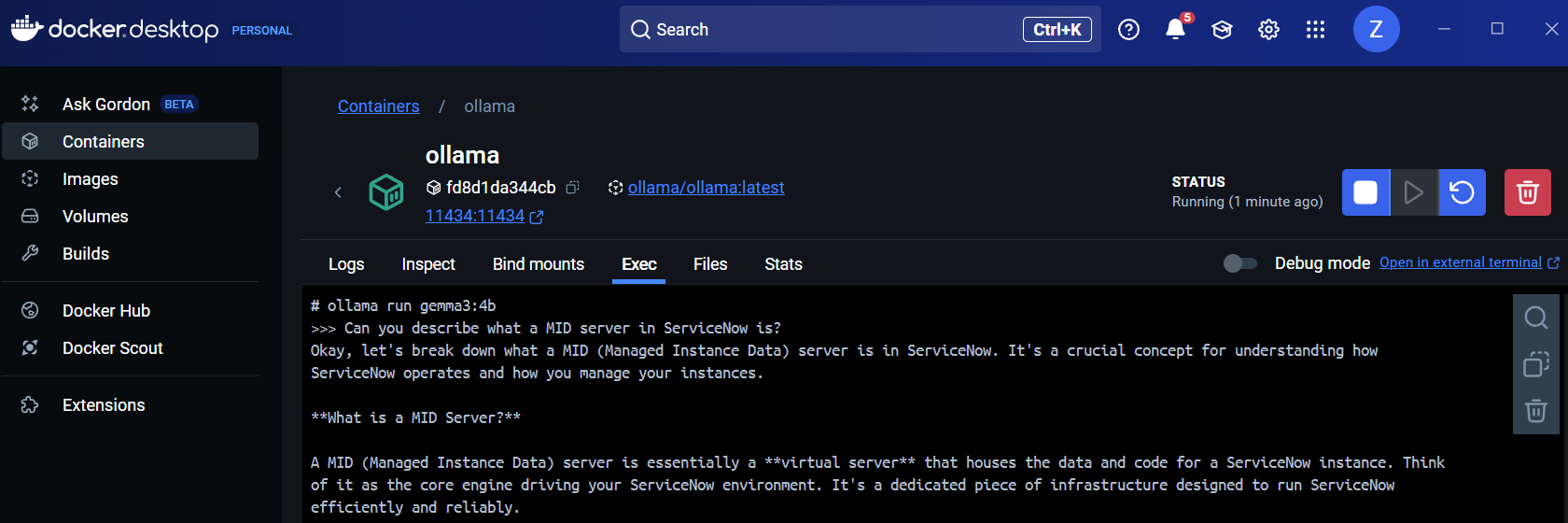
Using Ollama in a ServiceNow Flow
Now let’s make ServiceNow talk to your local AI model. I created a flow that sends a JavaScript snippet to the model for code review and gets a response with Danish comments added.:
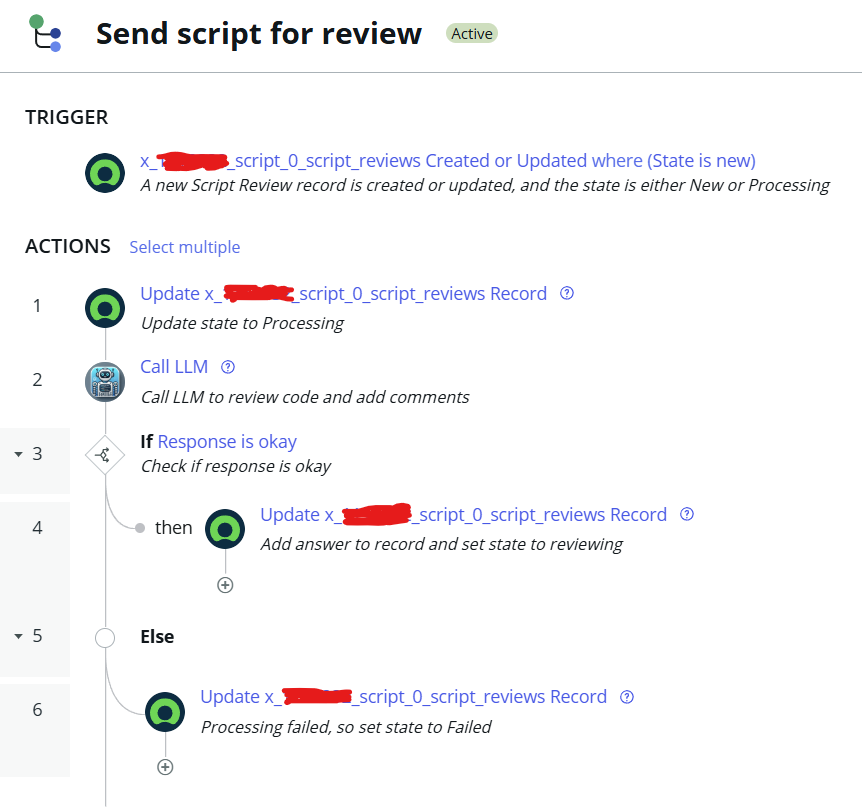
The interesting part is the Call LLM action, which is responsible for getting the answer from the LLM in Ollama. Begin by creating a new Flow Action:
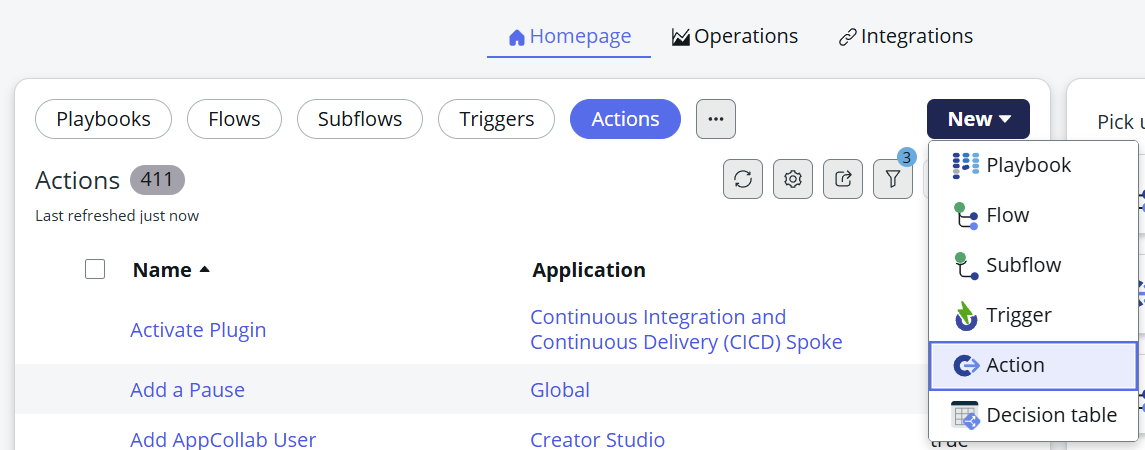
Define the input that will be given to the Flow Action:

The next step is a Script step, which will build the JSON payload that will be sent to the Ollama API using the MID Server:
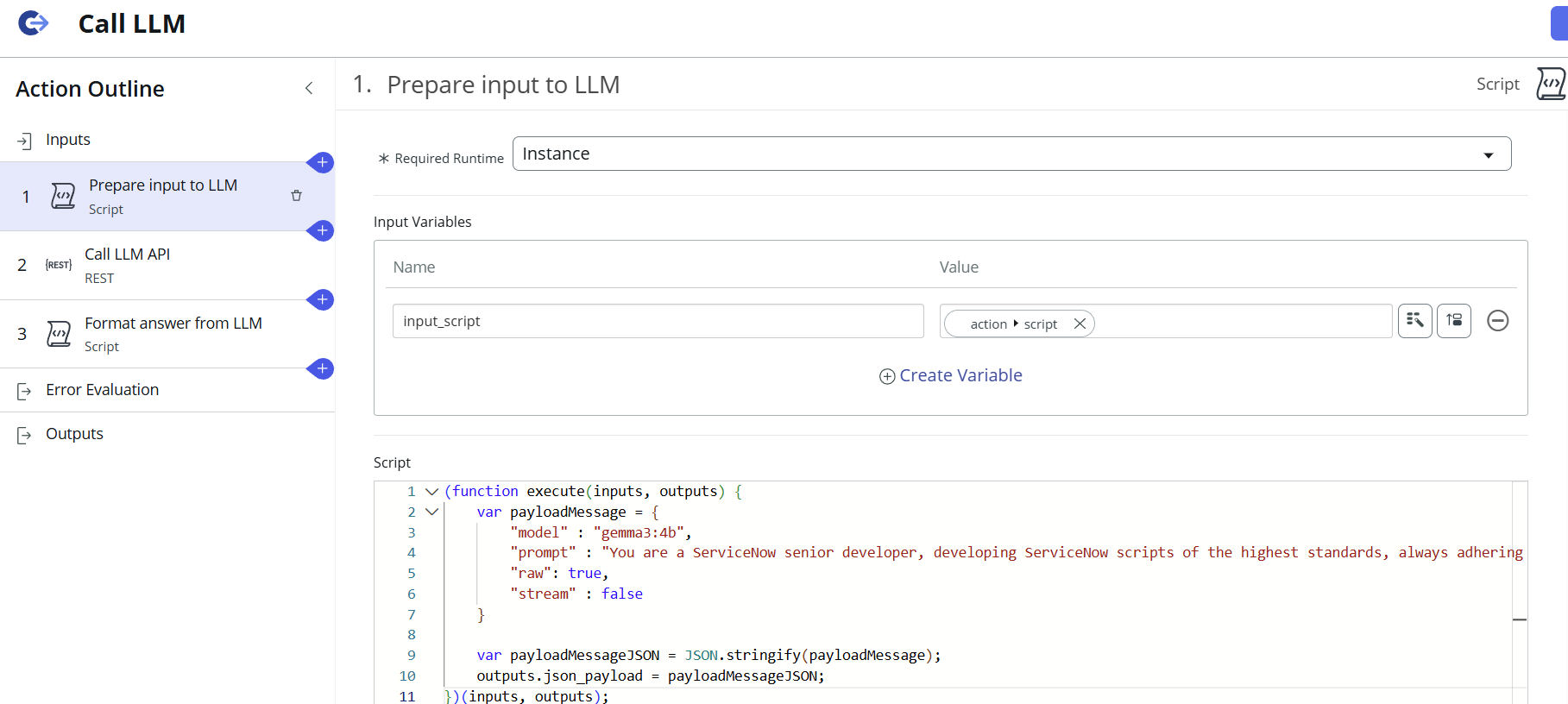
There are a few important parameters to note here:
The full function used in this example can be seen here:
(function execute(inputs, outputs) {
var payloadMessage = {
"model" : "gemma3:4b",
"prompt" : "You are a ServiceNow senior developer, developing ServiceNow scripts of the highest standards, always adhering to best practices. Do not generate any markdown or markdown markup in your response, this is very important. I can not use your response if it contains markdown. You are tasked with reviewing and improving the scripts given to you for review. Add comments in Danish to the code to make it easier to understand. All comments added should be in Danish. It is very important that you add the Danish comments. Your output is being used directly, so only output the script and nothing else. Do not include headers. Do not wrap the response with markdown tags. Do not put anything around the script that is given to you as input. The script that you are outputting will be put directly into the codebase, so the output that you are generating must be usable JavaScript. The script you are going to review is: " +inputs.input_script + "",
"raw": true,
"stream" : false
}
var payloadMessageJSON = JSON.stringify(payloadMessage);
outputs.json_payload = payloadMessageJSON;
})(inputs, outputs);
The next step is to add a REST step:
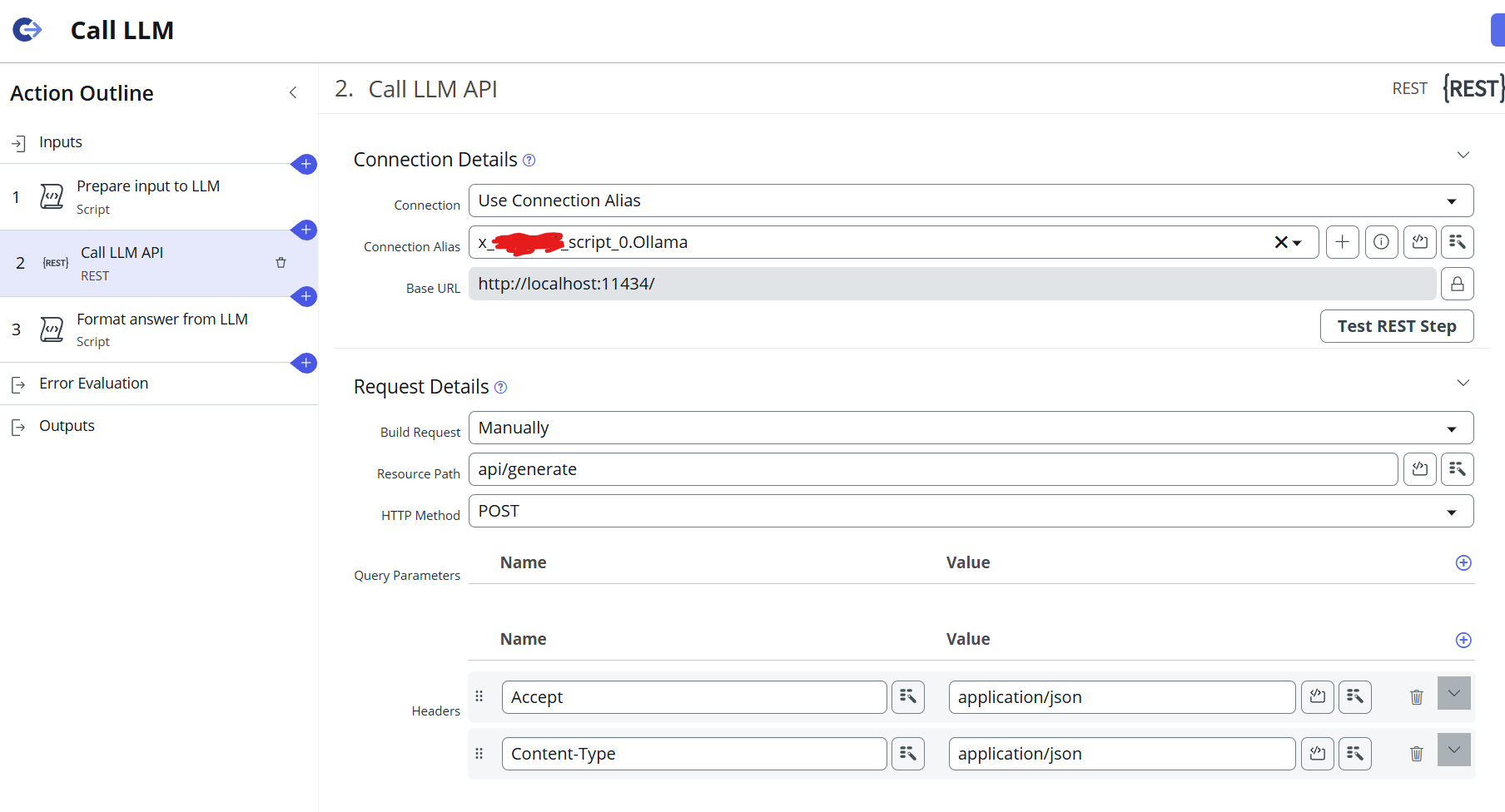
It is important to set the Base URL to localhost, since the Ollama API is running on the same machine that the MID server is running on. The port needs to be set to the port set earlier for the Ollama API: 11434. Be sure to also set the headers as shown in the screenshot above.
Finally, the answer from the LLM is retrieved and formatted in the last Script step:
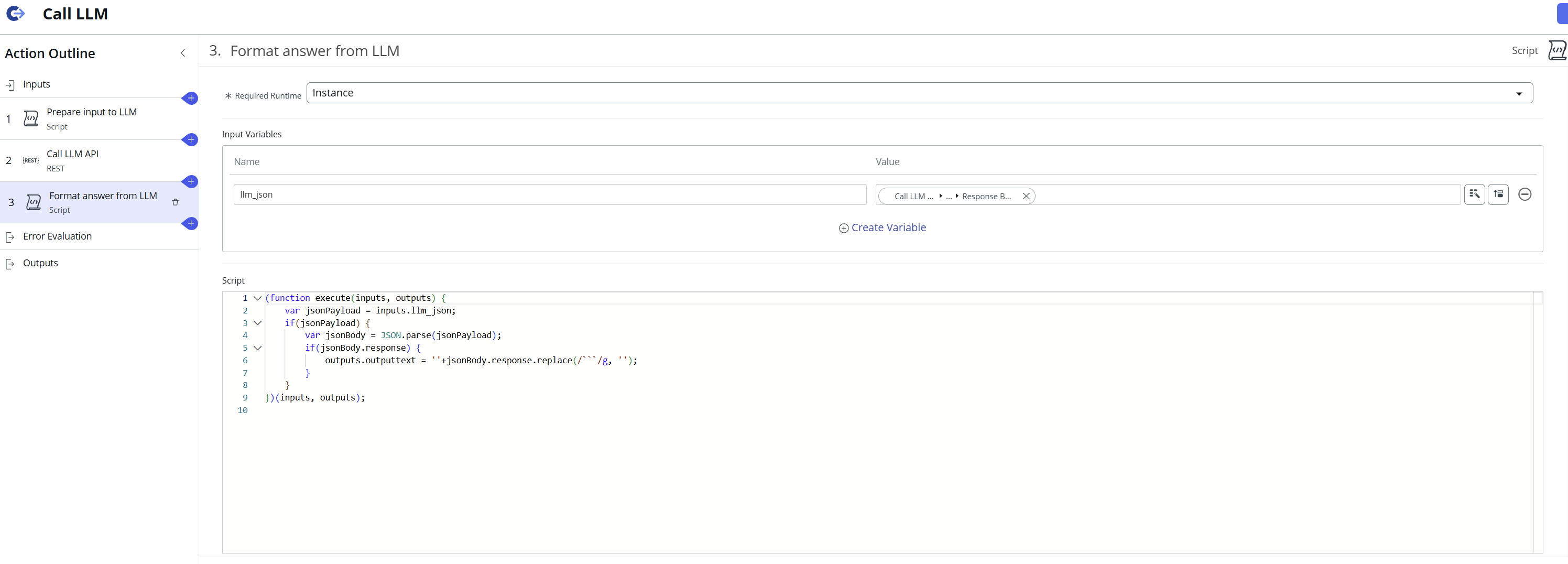
Now the Flow Action can be used in a Flow in ServiceNow, where LLM processing is required. I have used it in a custom application for reviewing scripts, which can be seen here:
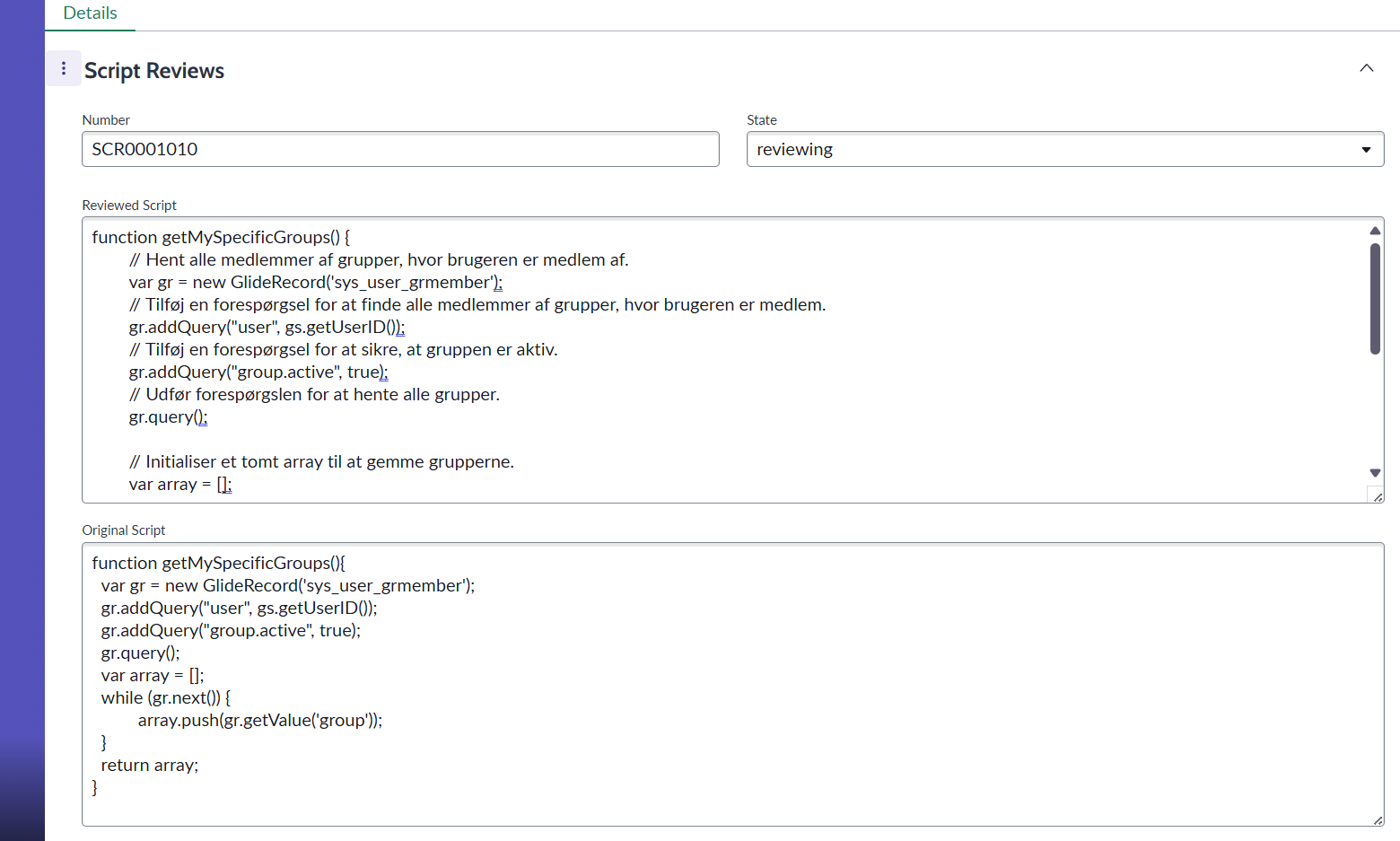
The Original Script field contains the script that was originally given as an input to the application. The Reviewed Script field contains the processed response from the LLM. In this example, it contains code comments in Danish, which is what the LLM was instructed to do.
Wrapping up
This setup opens up a lot of possibilities. You can now:
Best of all, your data never leaves your machine. Whether you’re testing ideas or building something for production, this local LLM integration is a flexible and powerful way to bring AI into ServiceNow.

